Google Books Extractor
Contents
- What is it and what does it do?
- How do I use it?
- What else do I need to know?
- Export Plugins
- License
- Thanks
- Contact
What is it and what does it do?
Google Books Extractor (due to laziness I will call it GBE from now on) is a little tool for the Google Book Search. The pages you see there are images and the GBE extracts the URLs of those images for you, enabling you to save them on your harddrive (for my fellow smartass nerds: Yes, I know the images are already there, but getting them from the browser cache is about as userfriendly as sniffing out the JSON response with Firebug or Wireshark and getting the URLs from there). This tool was build for people who need access to certain pages from a book without having to go online to search for them again and do not have the technical knowledge to retrieve the needed information. It was also build for people who do have the knowledge how to do this but who are too lazy to manually extract the URLs for dozens of pages (aka: me ;)).
I mentioned it under »What else do I need to know?«, but since people (including me) tend not to read stuff:
This is a very early release, expect it to have errors!
Just for the record: I am not affiliated with Google (or any of their products or services) in any way and this little tool is nothing official.
How do I use it?
GBE is deployed as a little bookmarklet (you could see it as a little Javascript application living in your browser, I guess) which will load the needed code from this project site. So what you need to do is to create a new bookmark in your browser (preferably within the bookmark toolbar) and paste the following code into the address field:
javascript:(function(){if(typeof window.GoogleBooksExtractor=='undefined'){window.GBE_SOURCE_BASE='http://gbe.saturnpolly.net/release/latest';window.GBE_PLUGIN_BASE='http://gbe.saturnpolly.net/release/plugins';window.GBE_PLUGINS=[GBE_PLUGIN_BASE+'/plain-min.js',GBE_PLUGIN_BASE+'/plain_numbered-min.js',GBE_PLUGIN_BASE+'/wget_shellscript-min.js',GBE_PLUGIN_BASE+'/wget_batchscript-min.js',GBE_PLUGIN_BASE+'/html_links-min.js'];var scriptEl=document.createElement('script');scriptEl.setAttribute('src',GBE_SOURCE_BASE+'/gbe-min.js');document.body.appendChild(scriptEl);}else{window.GoogleBooksExtractor.show();}})();
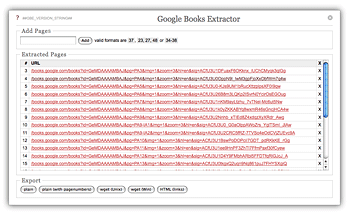
Now when you are viewing any book or magazine from Google Books Search you can click on your bookmarklet to load the GBE. Add pages by typing the page numbers (or ranges) into the input field and click »Add« or hit the return-key. GBE will add the pages to the table in the middle and then try to get the image URLs, showing you a little message box when it is done. You can still add more pages while it is loading or after all the URLs were retrieved. As long as you do not reload the page or navigate back and forth you can also close the GBE window in between and restore it by clicking on your bookmarklet again.
You can then download the images by rightclicking on the URLs and selecting »Save to disk« (or whatever it is called in your browser) or you can use one of the built in export plugins to save (more or less) the extracted pages and use somekind of download manager or whatever you like.
Wait a minute …
… isn't it generally a bad idea to include third party Javascript in a website? It is. By including the Javascript for GBE on a Google site you give the code the same permissions like the Google Javascript. This makes it possible for GBE to do AJAX-Requests and get the page URLs, but it also would be possible to read your cookies and send the information to any other site.
GBE does not collect any data from you and communicates only with the Google website. The code is available for everyone, feel free to check. If you don't trust me not to change that in the future you may host, use and redistribute your own copy (there is basically no license).
What else do I need to know?
So far GBE has been successfully tested with Firefox 3 and Safari 3, other browser might be supported in the future, but Internet Explorer will come in last for sure. Also you should recognize that GBE is in an very early stage right now and not widely tested, so you should not expect it to run without any problems on every book (though it cannot break your browser). If you find a book where GBE does not work feel free to contact me. Providing me the following details helps a lot: The exact book url, your browser (including the exact version) and what exactly »not working« means in your case (At what point does the error occur? Is there any error message?).
If GBE suddenly stop working for you at all from a specific version you can always switch back to a previous release. The plugins however are not versioned, since they are not very complex and probably won't change a lot.
Depending on the document Google Books Search does not count things like the cover as pages. so you might be looking at the third scanned image of the document but in the top right corner Google tells you this is page 1. GBE does not make this distinction, the first page you see is page 1, no matter if it is a cover, a table of contents or an advertisment.
You should also know that the links in the result table will be opened in the existing tab or window (mostly because I think, that a website or webapp should not tell the user how hey should use his browser), so if you do not want to leave the Google Books Search document and loose the retrieved image URLs you will have to open an image in a new tab or window.
Export Plugins
Having the image URLs is nice, but having to manually download the images still sucks. Therefore GBE supports export plugins, which will allow to transform the retrieved pages and the associated pagenumbers into a stringified version that is useful for some programm (i.e. wget).
GBE comes with 5 built in export plugins:
-
wget Shellscript
The output of this plugin can be saved as a shellscript, that will use wget to download all retrieved images and save them with the pagenumber in the filename (with leading zeros so they can be properly sorted by name).
(I'm not very shell-savvy. If you are and you cried while reading this plugin's output feel free to contact me and tell me how I could improve it.)
-
wget Batchscript
This does the same as the shellscript version but can be used in Microsoft Windows. Please note, that contrary to unix-style operating system Windows comes not bundled with things like wget, so will have to manually download a binary for Windows and make sure it is available in one of the PATH directories (if you don't know what that is just put the executable and the needed libraries in C:\Windows).
-
Plaintext (URLs only)
This will just list the urls sorted by pagenumber. It might not be useful for everybody but I thought there should be a very basic way to output the retrieved URLs.
-
Plaintext (with pagenumbers)
Same as above, but the URLs are preceded by the pagenumber.
-
HTML
This plugin is useful if you have a download manager that can extract urls from a document (for example the Firefox addon DownThemAll). Just save the output from this plugin as a HTML document and open it. DownThemAll can extract the links and if you set *text* as renaming scheme it will use the linktext as filename.
Why is there no »Download all the pages as one ZIP-file«-plugin?
Although this would be technically possible by piping the image URLs to my website, download them for you and give you one file containing all the images there are two problems with this:
- Doing this burdens my webspace with a lot of load and traffic and if many users do this my webspace provider will take all my money and I have to live on the street. Not enough as a reason? Carry on reading then.
- Copyright law. The GBE only retrieves the location of the images for you, you can then download them for your personal use (this is called fair use and should be legal in every legislation), however if I download the images for you and provide you the possibility to download them from me this would be called unauthorized redistribution of copyrighted material. So now not only do I have no home, I also have to go to prison. Happy now?
So you see, I really cannot do this for you. However if you have the technical knowledge how to do this, webspace or a server and write your own export plugin for yourselve I would say the load would be bearable and again it would fall under personal use.
Adding your own plugin
You can load additional export plugins by adding an URL to the script-array in the bookmarklet. Here is an example:
(function()
{
window.GoogleBooksExtractor.addExportPugin({
name:'foo', // a-zA-Z0-9_
title:'Export as foo', // used for the button
callback:function(pages, bookInfo) // called when button is clicked
{
return "your stringified version of the pages";
}
});
})();
Your callback function will receive two arguments, both simple objects that are used as associative pseudo-array. The first one uses the pagenumbers as keys and and contains more objects in the form of {pid:[Google's internal page id], src:[the URL of the image]}. The second argument has the following keys: id, pageCount.
The global String-object also has been extended with a method called pad, it recieves 2 mandatory and 1 optional argument (char, int, boolean): The character that is used for padding, the length of the string after the padding has been applied and the optional boolean argument, setting it to true will apply the padding on the right side. This comes in handy if you want to adjust different pagenumbers (001, 013, 137).
Contact me if you end up building something useful.
License
GBE is not released under a specific license (mostly because I hate bureaucracy of any kind). As long as the link to this original documentation is not removed you may feel free to change and/or redistribute this script. If you have changes that might be useful to others I would be thankful for some kind of notice so I can distribute these changes to existing users or at least let users know, by linking to your stuff from this document.
Thanks
First of all I want to thank Eva, who gave me the idea to build this tool by asking if it was possible to save pages from Google Books Search. Another big thank you goes to the guys developing Firebug. I cannot even count the hours this extension has saved me in the last years and though it certainly would have been possible to build the GBE without this extension it would have been a pain in the ass!
Contact
If you have problems with the GBE, have written a fancy export plugin or simply want to tell me what a nice guy I am you may use following mail address:
Paul Styrnol <mail@saturnpolly.net>